The promise of AI for public policy is well established. Less discussed is the foundational challenge that precedes it: the data on which such systems depend is often fragmented, inconsistent, or simply absent. TANGO addresses that gap directly – building tools and datasets that give policy makers something more useful than algorithmic confidence: genuine contextual understanding.
Supporting policy makers in shaping social welfare policies
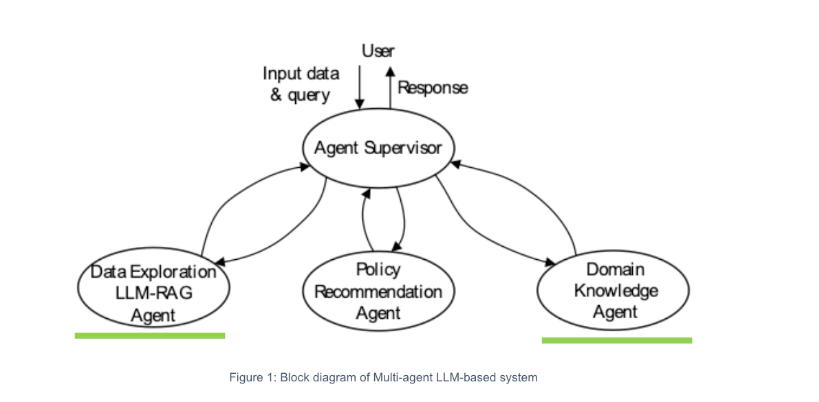
One of the key contributions of the TANGO project is the development of a Multi-Agent AI Framework designed to support policy makers, particularly in complex domains such as social welfare. These systems are not intended to automate decision-making, but to assist institutions in navigating fragmented data sources, identifying patterns, and testing policy scenarios
In this context, I contributed as a representative of the SHARE Foundation, working alongside partners from the Institute for Artificial Intelligence of Serbia, the A11 Initiative, and the Ministry for Family Care and Demography. The collaboration brings together expertise across technology, law, and public policy, ensuring that AI tools remain grounded in the public interest, fundamental rights, and institutional realities.
Challenges in developing the primary use case
The development of the initial use case, focused on social welfare policies in Serbia, has encountered significant obstacles. The central difficulty is access to high-quality, structured, and reliable data, which is often scarce in socially sensitive domains.
These challenges are compounded by the inherently dynamic nature of public administration, where shifts in government structures, leadership, and administrative priorities are an inevitable feature of the institutional landscape. For projects that depend on close co-operation with ministries, such transitions can affect timelines, restrict data access, or necessitate adjustments in coordination. Sustaining research continuity under these conditions calls for flexibility, mutual understanding, and consistent engagement across all stakeholders.
Rather than abandon the original use case, the project consortium has decided to run a parallel track built on the same principles: supporting policy makers in shaping artificial intelligence policy. The two streams reinforce rather than compete with one another, and together they strengthen the overall results.
From constraints to opportunity: Alternative data and contextual knowledge
The alternative use case is built on the concept of Alternative Data and Contextual Knowledge, which extends the AI framework beyond conventional administrative datasets. Rather than relying solely on institutional data, the approach draws on diverse sources that offer broader insights into policy ecosystems.
To support this shift, we prepared three specific datasets:
- Serbia AI Ecosystem dataset (800+ entities, ~1000 projects), mapping key actors and initiatives
- AI policy documents dataset (200+ documents in 10 languages), covering laws, strategies, guidelines, and action plans from Serbia and across Europe
- The Language of Trustworthy AI, a glossary of approximately 450 terms related to AI governance and ethics
These datasets were integrated into the TANGO framework, followed by a dedicated workshop with SHARE partners and ongoing feedback sessions. The scale and diversity of the material enabled the development of a complementary AI tool in a different policy domain, constructed on the same methodological principles. This parallel development not only broadened the analytical reach of the system, but also stress-tested the framework across multiple contexts, reinforcing the original use case in the process.
Particularly valuable was the inclusion of local data on the Serbian AI ecosystem, which brought a grounded, context-rich perspective to the analysis. The dataset maps more than 800 entities and approximately 1000 projects, offering insights into actors, relationships, and development trajectories that define the field. Its visualisation captures the structure and dynamics of the ecosystem in ways that aggregate statistics alone cannot – and can be explored in detail below:
| For embedding: https://embed.kumu.io/a821004b7a10468f574b985a017a1ed1 <iframe src=”https://embed.kumu.io/a821004b7a10468f574b985a017a1ed1″ width=”940″ height=”600″ frameborder=”0″></iframe> |
Serbia AI Ecosystem tool jointly created by UNDP Serbia and the Office for IT and eGovernment, with support from an expert team at the Faculty of Organizational Sciences, University of Belgrade, led by Prof. Krivokapić.
Mapping AI policy: a multilingual and multi-level dataset
At the core of this alternative use case is the AI policy documents dataset, originally collected and curated by the SHARE Foundation research team. It offers a structured overview of how AI is governed across different jurisdictions, serving as the principal source of comparative insight within the framework.
The dataset comprises over 200 documents in more than 15 languages, organised across three levels:
- European-level policies – including strategic frameworks, regulatory proposals, and guidelines developed at the EU level
- Policies of EU Member States – national AI strategies, legislative acts, and implementation plans reflecting diverse regulatory approaches
- Regional context (Serbia and Montenegro) – policy documents capturing alignment efforts, strategic priorities, and ongoing reforms in candidate countries
The structure of the dataset enables comparative analysis across jurisdictions, policy types, and thematic areas. Documents are categorised by type (law, strategy, guideline, action plan), geographic scope, language, and policy domain – allowing researchers and policy makers to identify trends, gaps, and points of convergence in AI governance.
More importantly, the dataset provides the foundation for integrating contextual knowledge into AI systems. By combining legal texts, strategic documents, and policy narratives, the framework moves beyond numerical data to incorporate the normative and institutional dimensions of decision-making.
AI Strategies in EU Member States
Twenty-four EU member states have now adopted strategic documents on AI, the majority of them emerging between 2018 and 2020. This early wave reflects a broad recognition of AI as a driver of both economic and societal transformation.
Yet, beneath this apparent maturity, certain gaps remain. The first is structural. Prior to the introduction of the AI Continent Action Plan, the European framework offered only limited guidance for national AI development, with the result that member states took markedly different approaches – varying in concept, scope, and architecture. Some strategies are predominantly policy-driven; others are innovation-focused. That diversity is not itself a problem, but it does complicate comparative analysis, slow cross-border alignment, and make evidence-based policy design considerably harder.
The second gap is evaluative. Many countries have completed or updated their strategies, yet systematic assessments of impact, effectiveness, and outcomes remain scarce. Without that layer of scrutiny, institutional learning stays partial. And underlying both issues is a constraint that is simply temporal: in many cases, it remains too early to judge reliably which measures have produced tangible results, and under what conditions. That makes the task of drawing conclusions – let alone recommending future policy directions – unusually complex in this domain.
These are the questions TANGO now addresses – confident that through data, comparison, and context, we can gradually convert these challenges into sharper insights and more effective tools for AI policy making.
Towards more informed and trustworthy policy making
The development of this alternative use case carries a broader lesson: when conventional data sources prove inadequate, innovation often lies in rethinking what qualifies as data. By integrating alternative datasets and contextual knowledge, AI systems can be made to reflect the genuine complexity of real-world policy environments.
The underlying aim remains unchanged. AI should not dictate policy outcomes. Its role is to help policy makers navigate complexity, explore options, and reach decisions that are transparent, accountable, and aligned with societal values – decisions that remain, ultimately, a human responsibility.
In shaping the future of AI governance, the question is not only what data we use, but how we interpret it, and who remains accountable for the decisions that follow.
Written by: Đorđe Krivokapić, PhD, is an Associate Professor of Information and Communication Technology Law at the Faculty of Organizational Sciences, University of Belgrade. His work spans ICT law, data protection, business ethics, and human resource management. As co-founder of the SHARE Foundation, he has led interdisciplinary efforts to protect digital rights and promote open knowledge. His academic and research engagements, including at Masaryk University and within Horizon projects such as TANGO and GEO-Power, provide a strong foundation for bridging regulatory frameworks and technological innovation.