
TANGO BLOGPOST
As Artificial Intelligence (AI), fueled by advances in deep learning, becomes more common in our daily lives – even in high-stakes applications like healthcare and self-driving cars – it becomes ever more important that we can trust AI systems.
While deep neural networks excel at processing low-level data – like images, language, videos, etc. – they also struggle with complying to known safety and structural constraints. For instance, such constraints may state that autonomous vehicles must always “stop” whenever there is a “pedestrian” on the road.
On the other hand, symbolic reasoning systems shine when it comes to logical inference and offer native support for prior knowledge, but are not designed to handle low-level data.
Neuro-Symbolic AI to the rescue!
Neuro-Symbolic AI (NeSy) combines the advantages of these approaches. In short, NeSy models introduce a symbolic reasoning step into neural architectures. One common recipe is as follows: first use a neural network to translate the low-level input into high-level symbols – or concepts – and then perform symbolic reasoning on the latter.
In autonomous driving, a NeSy model would take an input dashcam image and converted it into symbols – representing how many “pedestrians” or “red lights” are visible in it – and then the reason about whether to “proceed” or “stop” based on these symbols and prior knowledge encoding traffic laws.
This way, NeSy models – such as DeepProbLog [0] – output reliable predictions that comply with prior knowledge. Moreover, the reasoning step can be inspected: humans can check what symbols lead to any prediction. This makes them ideal for high-stakes applications that require both transparency and precise control over the model’s behavior.
A new challenger appears: reasoning shortcuts.
The success of these models largely depends on the quality of the learned symbols. For instance, if the model were to learn symbols that confuse the notion of “pedestrian” with that of “red lights”, this might lead to very poor down-stream decisions.
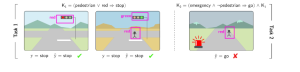
Unfortunately, this can happen. In fact, Marconato et al. [1] have shown that such models can achieve high performance by relying on concepts with unintended meanings. These are known as Reasoning Shortcuts.
Example: A self-driving car has to decide whether to “stop” or “go” (as in the picture) depending on whether it sees a “red light”, “a green light”, or “a pedestrian” on the road. Left: The car knows that “if there’s a red light or a pedestrian, then stop.” Surprisingly, the model can learn to correctly classify its training data by confusing pedestrians and red lights, as both lead to the same, correct action (“stop”).
This is a Reasoning Shortcut, and it’s not good! In fact, Reasoning Shortcuts undermine the system’s trustworthiness and interpretability. Imagine the model in the example is then used for driving an ambulance (right in the picture), whose rule is: “in emergencies, the ambulance can ignore red lights.” If the model thinks that pedestrians are red lights, it could mistakenly run over them! Moreover, users inspecting this decision would be fooled that the model has indeed seen a “red light”, when in fact it detected a “pedestrian”.
Can we recognize Reasoning Shortcuts?
It turns out that Reasoning Shortcuts are a tough nut to crack. Most NeSy models are not designed to avoid them, and doing so requires expensive mitigation strategies [1].
But there is an alternative: instead of avoiding Reasoning Shortcuts altogether, which is hard, we can much more cheaply Neuro-Symbolic models are aware of the semantic ambiguity of the concepts they learn.
Within TANGO, we developed BEARS [2], a technique rooted in Bayesian uncertainty calibration that does not require additional data. In short, BEARS constructs a collection of NeSy models learned specifically so that they disagree on what concepts they predict. This means that different models will learn different Reasoning Shortcuts. Then BEARS averages their predictions to produce a decision. Concepts whose meaning can be mixed up by the network end up averaging each other out, leading to increased uncertainty, while concepts that cannot be confused do not.
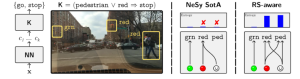
In short, with BEARS, users can easily identify and distrust low-quality concepts based on their uncertainty, paving the way to more robust and trustworthy Neuro-Symbolic AI.
Example: A single Neuro-Symbolic model can be overconfident about the symbols it learned – regardless of their quality! In the picture (middle), the model conflates “pedestrians” and “red lights”, yet it is dead certain about its predictions. BEARS instead averages together distinct Reasoning Shortcuts (right) such that the poor quality concepts become much more uncertain, while the high-quality ones do not. Now users can figure out that they should not trust the concepts of “pedestrian” and “red light” learned by the model!
[0]: Manhaeve, Dumancic, Kimmig, Demeester, & De Raedt. “Deepproblog: Neural probabilistic logic programming.” NeurIPS, 2018.
[1]: Marconato, Teso, Vergari, & Passerini, A. “Not all neuro-symbolic concepts are created equal: Analysis and mitigation of reasoning shortcuts.” NeurIPS, 2024.
[2]: Marconato, Bortolotti, van Krieken, Vergari, Passerini, & Teso. “BEARS make Neuro-Symbolic models aware of their Reasoning Shortcuts.” UAI, 2024.
Written by: Samuele Bortolotti and Stefano Teso, University of Trento